本文由HollisChuang 翻译自 The Top 100 Java Libraries in 2017 - Based on 259,885 Source Files . 原作者:Henn Idan
一年的时间就这么匆匆过去了,就好像像我们昨天才刚刚从GitHub上分析了2016年的Top Java类库一样。今年,我们在数据检索方面采用了Google的BigQuery,来得到更精确的结果。
译者注:BigQuery 是 Google 专门面向数据分析需求设计的一种全面托管的 PB 级低成本企业数据仓库。该服务让开发者可以使用Google的架构来运行SQL语句对超级大的数据库进行操作。BigQuery 可在几秒内扫描 1 TB 的数据,在几分钟内扫描 1 PB 的数据。
首先,我们按照star数排名,从GitHub上拉取了前1000份Java代码仓库,然后过滤掉Android项目,剩下477个纯Java项目。
我们基于这477个纯Java项目进行了分析。我们去重之后统计了所有的类库的import。更深入的关于统计方法的介绍在文章底部。
废话不多说,让我们来看看2017年最受欢迎的Java类库都有哪些?今年又是谁稳坐第一的宝座。
最受欢迎的前20个Java类库
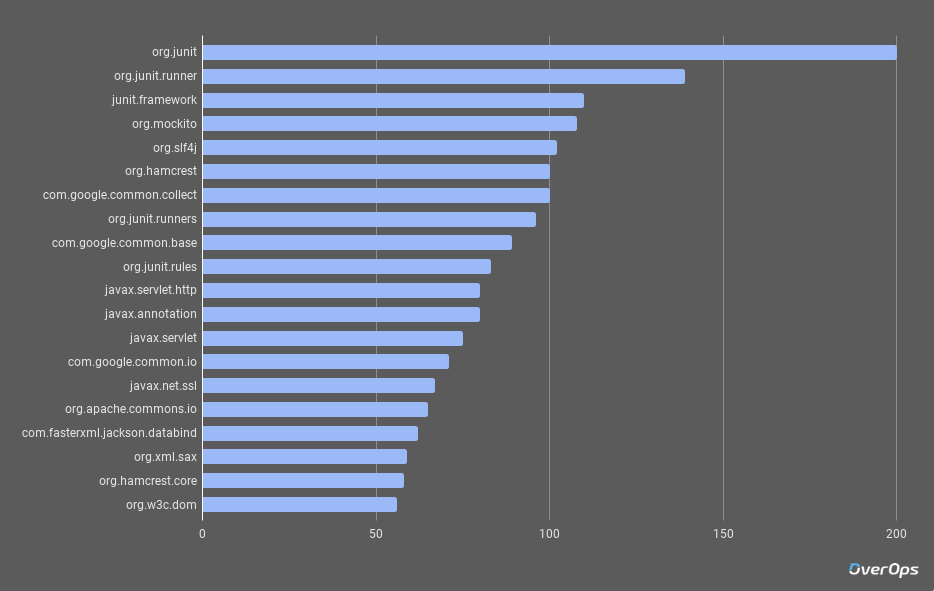
和去年一样,排名第一的类库,依旧是JUnit。基于它扩展的 JUnit Runner 占据第二名的位置,甚至是较旧的 junit.framework 此次也在第三名的位置。也就是说JUnit包揽了前三甲。
Mockito,这个开源的mock测试框架排名第四。
译者注:Mockito 是一个强大的用于 Java 开发的模拟测试框架, 通过 Mockito 我们可以创建和配置 Mock 对象, 进而简化有外部依赖的类的测试.
Java中的日志组建 slf4j 位列第五。这从某个侧面体现出目前的开发人员对日志还是比较情有独钟的。同时也看得出Java开发人员对于 java.util.logging 库的使用率较低。我们也曾经分析过Java开发者使用日志的一些习惯和偏好。整理在eBook中。
Hamcrest类库排名的上升,说明了开发人员确实是需要更好的测试环境。
译者注:Hamcrest是一个协助编写用Java语言进行软件测试的框架。它支持创建自定义的断言匹配器(assertion matchers)(名称“Hamcrest”即为“matchers”的异位构词),允许声明式定义匹配规则。这些匹配器在单元测试框架(例如JUnit和jMock)中有用。
分析排名在前几名的类库我们发现,测试对于写出更好的代码是十分重要的。这也就说明了一个事实,出现线上问题是开发者最不想看到的,所以我们会想尽一切办法去避免他的发生。(这部分还有一些关于作者网站的广告,我就不翻译了。)
Google的Guava类库排名第 7。 最受欢迎的JSON类库是Jackson 。 榜单第20名,是一个新晋类库:org.w3c.dom 。它提供了一系列操作DOM的接口。
其他值得我们注意的类库
纵观前100名,我们发现Spring 有很好的表现。以下8个类库进入前100 :
#57 – org.springframework.beans.factory.annotation
#60 – org.springframework.context
#65 – org.springframework.context.annotation
#66 – org.springframework.stereotype
#68 – org.springframework.util
#81 – org.springframework.test.context.junit4
#85 – org.springframework.beans.factory
#91 – org.springframework.web.bind.annotation
除了Spring之外,Apache的类库也有广泛的应用:
#16 – org.apache.commons.io
#22 – org.apache.http
#24 – org.apache.commons.lang
#25 – org.apache.http.impl.client
#30 – org.apache.http.client
#33 – org.apache.http.client.methods
#34 – org.apache.log4j
#35 – org.apache.commons.codec.binary
#45 – org.apache.commons.lang3
#53 – org.apache.http.entity
#61 – org.apache.http.util
#64 – org.apache.commons.logging
#75 – org.apache.http.message
#88 – org.apache.zookeeper
#95 – org.apache.hadoop.conf
#98 – org.apache.http.client.config
#100 – org.apache.http.client.utils
译者注:看到apache类库有这么好的表现,笔者比较开心。笔者一直崇尚不要重复制造轮子,我们日常开发中可能用到的一些方法在apache的类库中具有最佳实现。比如处理IO流、处理集合等。
在今年的排名中,AssertJ较去年有明显的提升,它为 Java 提供了流式断言(Fluent assertions)。今年它攀升至 50 名。
我们在榜单中也发现了 javax.script和 org.apache.http.client.utils这两个脚本API。
脚本API供那些希望在其 Java 应用程序中执行用脚本语言编写的程序的应用程序编程人员使用。
分析方法
文章开通我们提及过,今年我们使用Google的BigQuery来处理数据。我们通过GitHub提供的API拉取了1000份仓库代码。在过滤掉Android、Arduino和一些过时的仓库后,我们还剩余259,885份Java源文件。我们对同一个仓库中使用的类库进行去重后,还剩余25,788份类库。
我们实际是怎么做的呢?
首先,我们创建一个仓库表,用来存储star数排名靠前的哪些类库,命名为java_top_repos_filtered:
SELECT
full_name
FROM
java_top_repos_1000
WHERE NOT ((LOWER(full_name) CONTAINS 'android') OR
(LOWER(full_name) CONTAINS 'arduino'))
AND ((description IS null) OR
(NOT ((LOWER(description) CONTAINS 'android') OR
(LOWER(description) CONTAINS 'arduino') OR
(LOWER(description) CONTAINS 'deprecated'))));
现在,我们有了排名靠前的类库的名字,然后我们把他们都拉取下来:
SELECT
repo_name,
content
FROM
[bigquery-public-data:github_repos.contents] AS contents
INNER JOIN
(
SELECT
id,
repo_name
FROM
[bigquery-public-data:github_repos.files] AS files
INNER JOIN
java_top_repos_filtered AS top_repos
ON
files.repo_name = top_repos.full_name
WHERE
path LIKE '%.java'
) AS files_filtered
ON
contents.id = files_filtered.id;
至此,我们有了每个项目的源代码,我们就要把去重后的import的语句过滤出来,然后在提取包名称。
SELECT
package,
COUNT(*) count
FROM
( //extract package name (exclude last point of data) and group with repo name (to count each package once per repo)
SELECT
REGEXP_EXTRACT(import_line, r' ([a-z0-9\._]*)\.') package,
repo_name
FROM
( //extract only 'import' code lines from *.java files
SELECT
SPLIT(content, '\n') import_line,
repo_name
FROM
java_relevant_data
HAVING
LEFT(import_line, 6) = 'import'
)
GROUP BY
package,
repo_name
)
GROUP BY
package
ORDER BY
count DESC;
最后,我们再进行一次过滤,确保没有Android, Arduino、过时的或者Java提供的原生的类库。
SELECT
*
FROM
java_top_package_count
WHERE
NOT ((LEFT(package, 5) = 'java.') OR
(LOWER(package) CONTAINS 'android'))
ORDER BY
count DESC;
至此,你就得到了一份2017年排名Top 100的Java类库的列表了。
最后的一点想法
一个主要的结论是:那些2016年受欢迎的类库,在2017年依旧受欢迎。这也说明,这些类库背后的开发者、团队或者公司都在努力的使这些类库更好。
这也意味着,如果你打算开始写自己的Java项目,或者日常的开发中,我们的电子表格可以提供一些好的建议。这些排名靠前的类库是不错的选择。