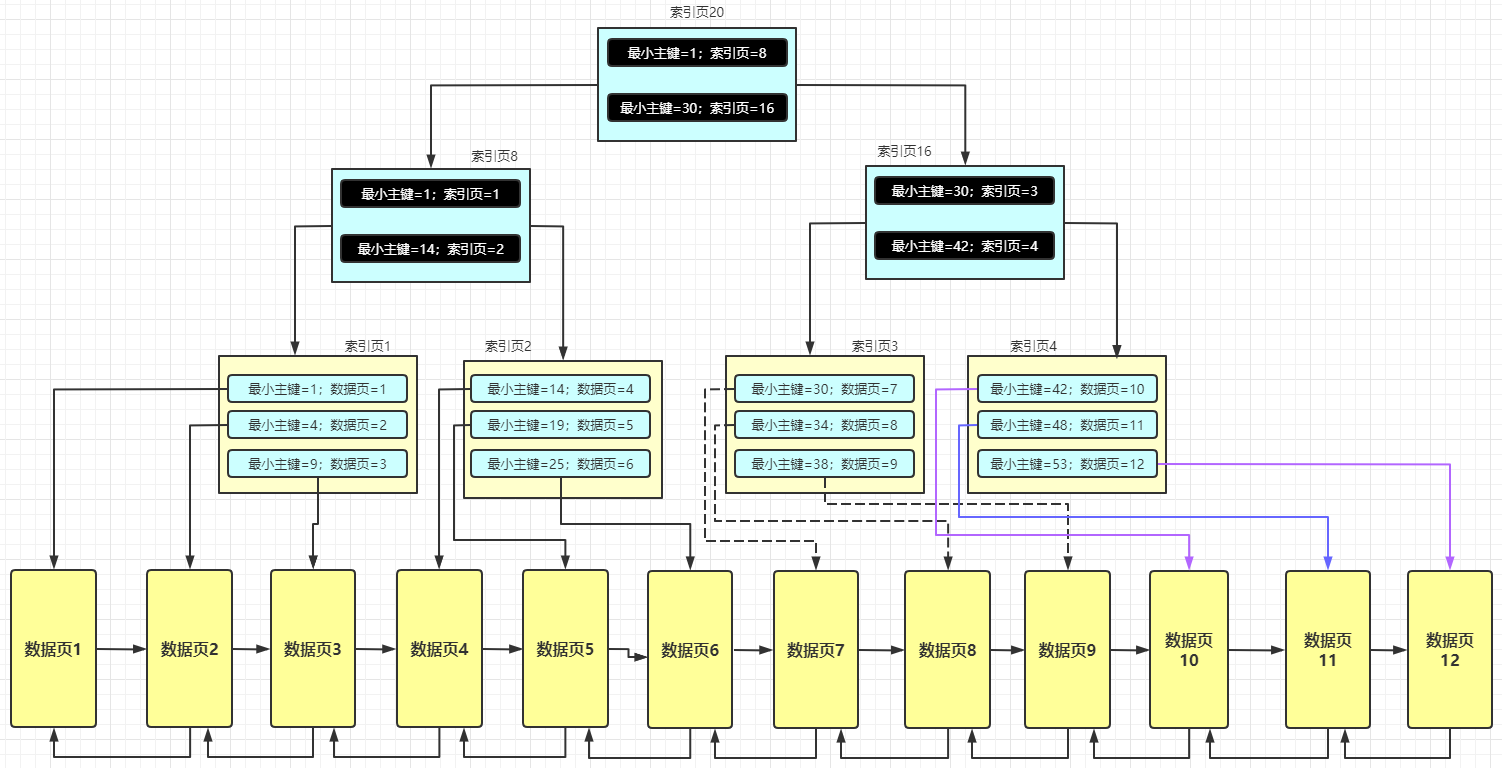
Innodb是MySQL的执行引擎,MySQL是一种关系型数据库,而Redis是一种非关系型数据库。这两者之间比较大的区别是:关系型数据库以表的形式进行存储数据,而非关系型数据库以Key-value的形式存储数据。
在InnoDB中,索引是采用B+树实现的,在Redis中,ZSET是采用跳表(不只是跳表)实现的,无论是B+树,还是跳表,都是性能很好的数据结构,那么,为什么InnoDB为什么不用跳表,Redis为什么不用B+树?
我们都知道,MySQL是基于磁盘存储的,Redis是基于内存存储的。
而之所以Innodb用B+树,主要是因为B+树是一种磁盘IO友好型的数据结构,而Redis使用跳表,是因为跳表则是一种内存友好型的数据结构。
B+树磁盘友好?
首先,B+树的叶子节点形成有序链表,可以方便地进行范围查询操作。对于磁盘存储来说,顺序读取的效率要高于随机读取,因为它可以充分利用磁盘预读和缓存机制,减少磁盘 I/O 的次数。
其次,由于B+树的节点大小是固定的,因此可以很好地利用磁盘预读特性,一次性读取多个节点到内存中,这样可以减少IO操作次数,提高查询效率。
还有就是,B+树的叶子节点都存储数据,而非数据和指针混合,所以叶子节点的大小是固定的,而且节点的大小一般都会设置为一页的大小,这就使得节点分裂和合并时,IO操作很少,只需读取和写入一页。
所以,B+树在设计上考虑了磁盘存储的特点和性能优化,我曾经分析过,当Innodb中存储2000万数据的时候,只需要3次磁盘就够了。(具体分析在我出的面试宝典中。)
而跳表就不一样了,跳表的索引节点通过跳跃指针连接,形成多级索引结构。这导致了跳表的索引节点在磁盘上存储时会出现数据分散的情况,即索引节点之间的物理距离可能较远。对于磁盘存储来说,随机访问分散的数据会增加磁头的寻道时间,导致磁盘 I/O 的性能下降。
为啥Redis用跳表
既然B+树这么多优点,为啥Redis要用跳表实现ZSET呢(不只是跳表,详见下面链接)?而不是B+树呢?
主要是因为Redis是一种基于内存的数据结构。他其实不需要考虑磁盘IO的性能问题,所以,他完全可以选择一个简单的数据结构,并且性能也能接受的 ,那么跳表就很合适。
因为跳表相对于B+树来说,更简单。相比之下,B+树作为一种复杂的索引结构,需要考虑节点分裂和合并等复杂操作,增加了实现和维护的复杂度。
而且,Redis的有序集合经常需要进行插入、删除和更新操作。跳表在动态性能方面具有良好的表现,特别是在插入和删除操作上。相比之下,B+树的插入和删除需要考虑平衡性,所以还是成本挺高的。
总结
以上,就是关于《InnoDB为什么不用跳表,Redis为什么不用B+树?》这个问题的我的一些理解,其实这个问题想要回答好还挺难的。
首先要知道为啥Innodb使用红黑树,其次还要了解Redis中的Zset数据结构,还需要知道跳表的原理。
和这个问题类似的问题还有:
Innodb为什么不用红黑树?Innodb为什么不用B树?
Redis的ZSet中zipList和skipList是什么?
为什么Redis 7.0中使用ListPack实现ZSet?
本文内容节选自我最近出的Java面试宝典,上面的这几个问题,在宝典中也都能找到答案,类似的问题及答案还有600多道题。
我们会持续更新内容,争取做到全网最新、最全、最准确的Java后端面试宝典。
之前在我抖音号上面卖了几天。现在已经卖了几百份了,而且,没有中差评!
因为要涨价了,所以,在公众号也发一下,弄了个微信小商店上面的链接,这个课程,是在线文档,永久更新的,并且没有时间限制。不需要你续费、也不需要二次消费。
大家可以通过下方二维码扫码购买,下单后根据短信提示申请权限并联系客服审批即可!