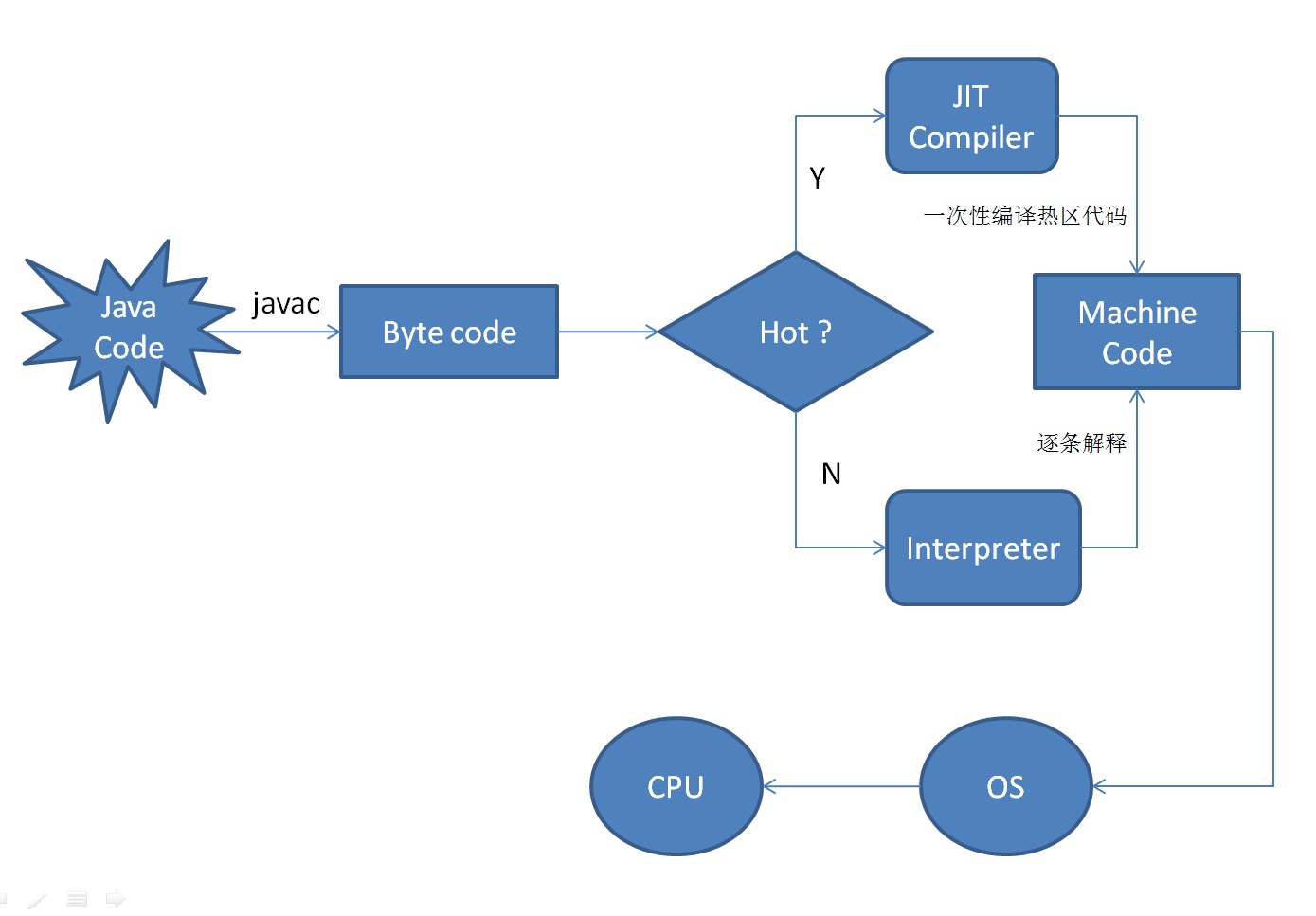
在Java的编译体系中,一个Java的源代码文件变成计算机可执行的机器指令的过程中,需要经过两段编译,第一段是把.java文件转换成.class文件。第二段编译是把.class转换成机器指令的过程。
第一段编译就是javac命令。
在第二编译阶段,JVM 通过解释字节码将其翻译成对应的机器指令,逐条读入,逐条解释翻译。很显然,经过解释执行,其执行速度必然会比可执行的二进制字节码程序慢很多。这就是传统的JVM的解释器(Interpreter)的功能。为了解决这种效率问题,引入了 JIT(即时编译) 技术。
引入了 JIT 技术后,Java程序还是通过解释器进行解释执行,当JVM发现某个方法或代码块运行特别频繁的时候,就会认为这是“热点代码”(Hot Spot Code)。然后JIT会把部分“热点代码”翻译成本地机器相关的机器码,并进行优化,然后再把翻译后的机器码缓存起来,以备下次使用。
由于关于JIT编译和热点检测的内容,我在深入分析Java的编译原理中已经介绍过了,这里就不在赘述,本文主要来介绍下JIT中的优化。JIT优化中最重要的一个就是逃逸分析。
逃逸分析
关于逃逸分析的概念,可以参考对象和数组并不是都在堆上分配内存的。一文,这里简单回顾一下:
逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸。
例如以下代码:
public static StringBuffer craeteStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb;
}
public static String createStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
第一段代码中的sb就逃逸了,而第二段代码中的sb就没有逃逸。
使用逃逸分析,编译器可以对代码做如下优化:
一、同步省略。如果一个对象被发现只能从一个线程被访问到,那么对于这个对象的操作可以不考虑同步。
二、将堆分配转化为栈分配。如果一个对象在子程序中被分配,要使指向该对象的指针永远不会逃逸,对象可能是栈分配的候选,而不是堆分配。
三、分离对象或标量替换。有的对象可能不需要作为一个连续的内存结构存在也可以被访问到,那么对象的部分(或全部)可以不存储在内存,而是存储在CPU寄存器中。
在Java代码运行时,通过JVM参数可指定是否开启逃逸分析,
-XX:+DoEscapeAnalysis : 表示开启逃逸分析
-XX:-DoEscapeAnalysis : 表示关闭逃逸分析 从jdk 1.7开始已经默认开始逃逸分析,如需关闭,需要指定-XX:-DoEscapeAnalysis
同步省略
在动态编译同步块的时候,JIT编译器可以借助逃逸分析来判断同步块所使用的锁对象是否只能够被一个线程访问而没有被发布到其他线程。
如果同步块所使用的锁对象通过这种分析被证实只能够被一个线程访问,那么JIT编译器在编译这个同步块的时候就会取消对这部分代码的同步。这个取消同步的过程就叫同步省略,也叫锁消除。
如以下代码:
public void f() {
Object hollis = new Object();
synchronized(hollis) {
System.out.println(hollis);
}
}
代码中对hollis这个对象进行加锁,但是hollis对象的生命周期只在f()方法中,并不会被其他线程所访问到,所以在JIT编译阶段就会被优化掉。优化成:
public void f() {
Object hollis = new Object();
System.out.println(hollis);
}
所以,在使用synchronized的时候,如果JIT经过逃逸分析之后发现并无线程安全问题的话,就会做锁消除。
标量替换
标量(Scalar)是指一个无法再分解成更小的数据的数据。Java中的原始数据类型就是标量。相对的,那些还可以分解的数据叫做聚合量(Aggregate),Java中的对象就是聚合量,因为他可以分解成其他聚合量和标量。
在JIT阶段,如果经过逃逸分析,发现一个对象不会被外界访问的话,那么经过JIT优化,就会把这个对象拆解成若干个其中包含的若干个成员变量来代替。这个过程就是标量替换。
public static void main(String[] args) {
alloc();
}
private static void alloc() {
Point point = new Point(1,2);
System.out.println("point.x="+point.x+"; point.y="+point.y);
}
class Point{
private int x;
private int y;
}
以上代码中,point对象并没有逃逸出alloc方法,并且point对象是可以拆解成标量的。那么,JIT就会不会直接创建Point对象,而是直接使用两个标量int x ,int y来替代Point对象。
以上代码,经过标量替换后,就会变成:
private static void alloc() {
int x = 1;
int y = 2;
System.out.println("point.x="+x+"; point.y="+y);
}
可以看到,Point这个聚合量经过逃逸分析后,发现他并没有逃逸,就被替换成两个聚合量了。那么标量替换有什么好处呢?就是可以大大减少堆内存的占用。因为一旦不需要创建对象了,那么就不再需要分配堆内存了。
标量替换为栈上分配提供了很好的基础。
栈上分配
在Java虚拟机中,对象是在Java堆中分配内存的,这是一个普遍的常识。但是,有一种特殊情况,那就是如果经过逃逸分析后发现,一个对象并没有逃逸出方法的话,那么就可能被优化成栈上分配。这样就无需在堆上分配内存,也无须进行垃圾回收了。
关于栈上分配的详细介绍,可以参考对象和数组并不是都在堆上分配内存的。。
这里,还是要简单说一下,其实在现有的虚拟机中,并没有真正的实现栈上分配,在对象和数组并不是都在堆上分配内存的。中我们的例子中,对象没有在堆上分配,其实是标量替换实现的。
逃逸分析并不成熟
关于逃逸分析的论文在1999年就已经发表了,但直到JDK 1.6才有实现,而且这项技术到如今也并不是十分成熟的。
其根本原因就是无法保证逃逸分析的性能消耗一定能高于他的消耗。虽然经过逃逸分析可以做标量替换、栈上分配、和锁消除。但是逃逸分析自身也是需要进行一系列复杂的分析的,这其实也是一个相对耗时的过程。
一个极端的例子,就是经过逃逸分析之后,发现没有一个对象是不逃逸的。那这个逃逸分析的过程就白白浪费掉了。
虽然这项技术并不十分成熟,但是他也是即时编译器优化技术中一个十分重要的手段。