之前的文章中我们介绍了Java 8中Stream相关的API,我们提到Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
那么,Stream API的性能到底如何呢,代码整洁的背后是否意味着性能的损耗呢?本文我们对Stream API的性能一探究竟。
为保证测试结果真实可信,我们将JVM运行在-server模式下,测试数据在GB量级,测试机器采用常见的商用服务器,配置如下:
| OS | CentOS 6.7 x86_64 |
| CPU | Intel Xeon X5675, 12M Cache 3.06 GHz, 6 Cores 12 Threads |
| 内存 | 96GB |
| JDK | java version 1.8.0_91, Java HotSpot(TM) 64-Bit Server VM |
测试方法和测试数据
性能测试并不是容易的事,Java性能测试更费劲,因为虚拟机对性能的影响很大,JVM对性能的影响有两方面:
- GC的影响。GC的行为是Java中很不好控制的一块,为增加确定性,我们手动指定使用CMS收集器,并使用10GB固定大小的堆内存。具体到JVM参数就是
-XX:+UseConcMarkSweepGC -Xms10G -Xmx10G - JIT(Just-In-Time)即时编译技术。即时编译技术会将热点代码在JVM运行的过程中编译成本地代码,测试时我们会先对程序预热,触发对测试函数的即时编译。相关的JVM参数是
-XX:CompileThreshold=10000。
Stream并行执行时用到ForkJoinPool.commonPool()得到的线程池,为控制并行度我们使用Linux的taskset命令指定JVM可用的核数。
测试数据由程序随机生成。为防止一次测试带来的抖动,测试4次求出平均时间作为运行时间。
实验一 基本类型迭代
测试内容:找出整型数组中的最小值。对比for循环外部迭代和Stream API内部迭代性能。
测试程序代码:
/**
* java -server -Xms10G -Xmx10G -XX:+PrintGCDetails
* -XX:+UseConcMarkSweepGC -XX:CompileThreshold=1000 lee/IntTest
* taskset -c 0-[0,1,3,7] java ...
* @author CarpenterLee
*/
public class IntTest {
public static void main(String[] args) {
new IntTest().doTest();
}
public void doTest(){
warmUp();
int[] lengths = {
10000,
100000,
1000000,
10000000,
100000000,
1000000000
};
for(int length : lengths){
System.out.println(String.format("---array length: %d---", length));
int[] arr = new int[length];
randomInt(arr);
int times = 4;
int min1 = 1;
int min2 = 2;
int min3 = 3;
long startTime;
startTime = System.nanoTime();
for(int i=0; i<times; i++){
min1 = minIntFor(arr);
}
TimeUtil.outTimeUs(startTime, "minIntFor time:", times);
startTime = System.nanoTime();
for(int i=0; i<times; i++){
min2 = minIntStream(arr);
}
TimeUtil.outTimeUs(startTime, "minIntStream time:", times);
startTime = System.nanoTime();
for(int i=0; i<times; i++){
min3 = minIntParallelStream(arr);
}
TimeUtil.outTimeUs(startTime, "minIntParallelStream time:", times);
System.out.println(min1==min2 && min2==min3);
}
}
private void warmUp(){
int[] arr = new int[100];
randomInt(arr);
for(int i=0; i<20000; i++){
// minIntFor(arr);
minIntStream(arr);
minIntParallelStream(arr);
}
}
private int minIntFor(int[] arr){
int min = Integer.MAX_VALUE;
for(int i=0; i<arr.length; i++){
if(arr[i]<min)
min = arr[i];
}
return min;
}
private int minIntStream(int[] arr){
return Arrays.stream(arr).min().getAsInt();
}
private int minIntParallelStream(int[] arr){
return Arrays.stream(arr).parallel().min().getAsInt();
}
private void randomInt(int[] arr){
Random r = new Random();
for(int i=0; i<arr.length; i++){
arr[i] = r.nextInt();
}
}
}
测试结果如下图:
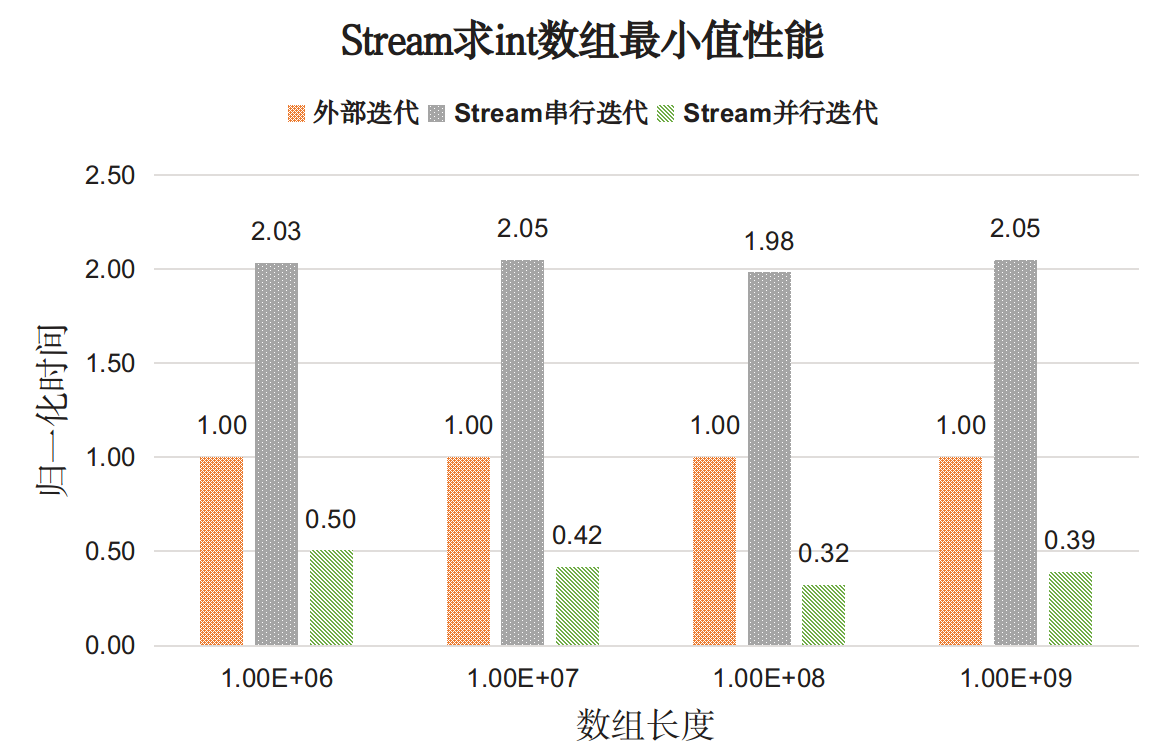
图中展示的是for循环外部迭代耗时为基准的时间比值。分析如下:
- 对于基本类型Stream串行迭代的性能开销明显高于外部迭代开销(两倍);
- Stream并行迭代的性能比串行迭代和外部迭代都好。
并行迭代性能跟可利用的核数有关,上图中的并行迭代使用了全部12个核,为考察使用核数对性能的影响,我们专门测试了不同核数下的Stream并行迭代效果:
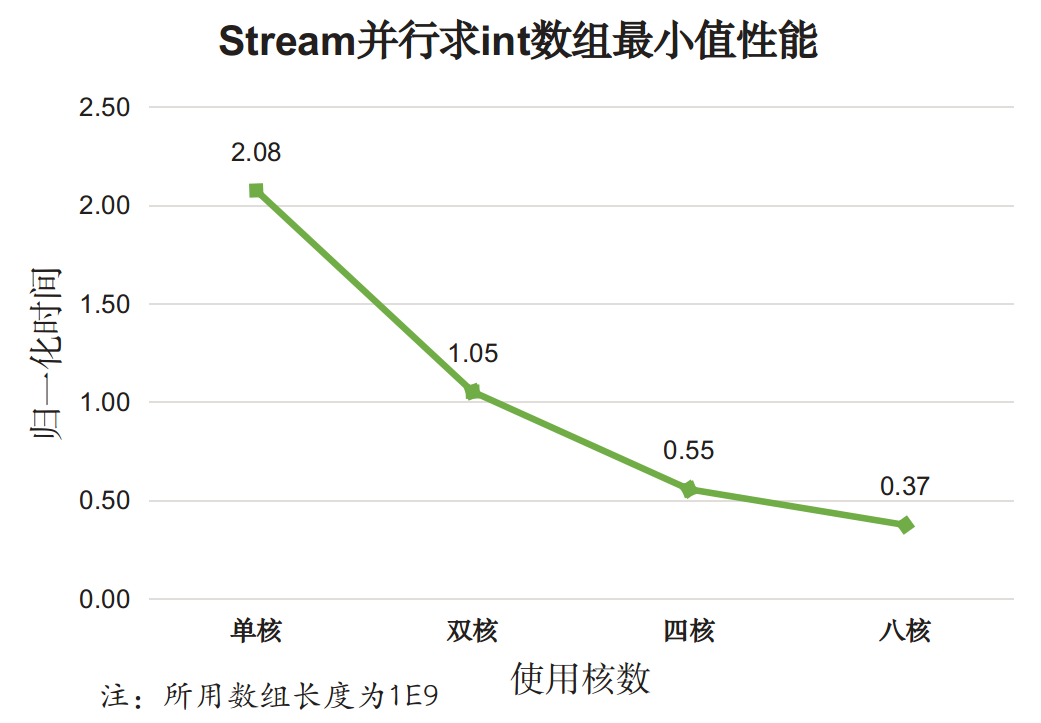
分析,对于基本类型:
- 使用Stream并行API在单核情况下性能很差,比Stream串行API的性能还差;
- 随着使用核数的增加,Stream并行效果逐渐变好,比使用for循环外部迭代的性能还好。
以上两个测试说明,对于基本类型的简单迭代,Stream串行迭代性能更差,但多核情况下Stream迭代时性能较好。
实验二 对象迭代
再来看对象的迭代效果。
测试内容:找出字符串列表中最小的元素(自然顺序),对比for循环外部迭代和Stream API内部迭代性能。
测试程序代码:
/**
* java -server -Xms10G -Xmx10G -XX:+PrintGCDetails
* -XX:+UseConcMarkSweepGC -XX:CompileThreshold=1000 lee/StringTest
* taskset -c 0-[0,1,3,7] java ...
* @author CarpenterLee
*/
public class StringTest {
public static void main(String[] args) {
new StringTest().doTest();
}
public void doTest(){
warmUp();
int[] lengths = {
10000,
100000,
1000000,
10000000,
20000000,
40000000
};
for(int length : lengths){
System.out.println(String.format("---List length: %d---", length));
ArrayList<String> list = randomStringList(length);
int times = 4;
String min1 = "1";
String min2 = "2";
String min3 = "3";
long startTime;
startTime = System.nanoTime();
for(int i=0; i<times; i++){
min1 = minStringForLoop(list);
}
TimeUtil.outTimeUs(startTime, "minStringForLoop time:", times);
startTime = System.nanoTime();
for(int i=0; i<times; i++){
min2 = minStringStream(list);
}
TimeUtil.outTimeUs(startTime, "minStringStream time:", times);
startTime = System.nanoTime();
for(int i=0; i<times; i++){
min3 = minStringParallelStream(list);
}
TimeUtil.outTimeUs(startTime, "minStringParallelStream time:", times);
System.out.println(min1.equals(min2) && min2.equals(min3));
// System.out.println(min1);
}
}
private void warmUp(){
ArrayList<String> list = randomStringList(10);
for(int i=0; i<20000; i++){
minStringForLoop(list);
minStringStream(list);
minStringParallelStream(list);
}
}
private String minStringForLoop(ArrayList<String> list){
String minStr = null;
boolean first = true;
for(String str : list){
if(first){
first = false;
minStr = str;
}
if(minStr.compareTo(str)>0){
minStr = str;
}
}
return minStr;
}
private String minStringStream(ArrayList<String> list){
return list.stream().min(String::compareTo).get();
}
private String minStringParallelStream(ArrayList<String> list){
return list.stream().parallel().min(String::compareTo).get();
}
private ArrayList<String> randomStringList(int listLength){
ArrayList<String> list = new ArrayList<>(listLength);
Random rand = new Random();
int strLength = 10;
StringBuilder buf = new StringBuilder(strLength);
for(int i=0; i<listLength; i++){
buf.delete(0, buf.length());
for(int j=0; j<strLength; j++){
buf.append((char)('a'+rand.nextInt(26)));
}
list.add(buf.toString());
}
return list;
}
}
测试结果如下图:
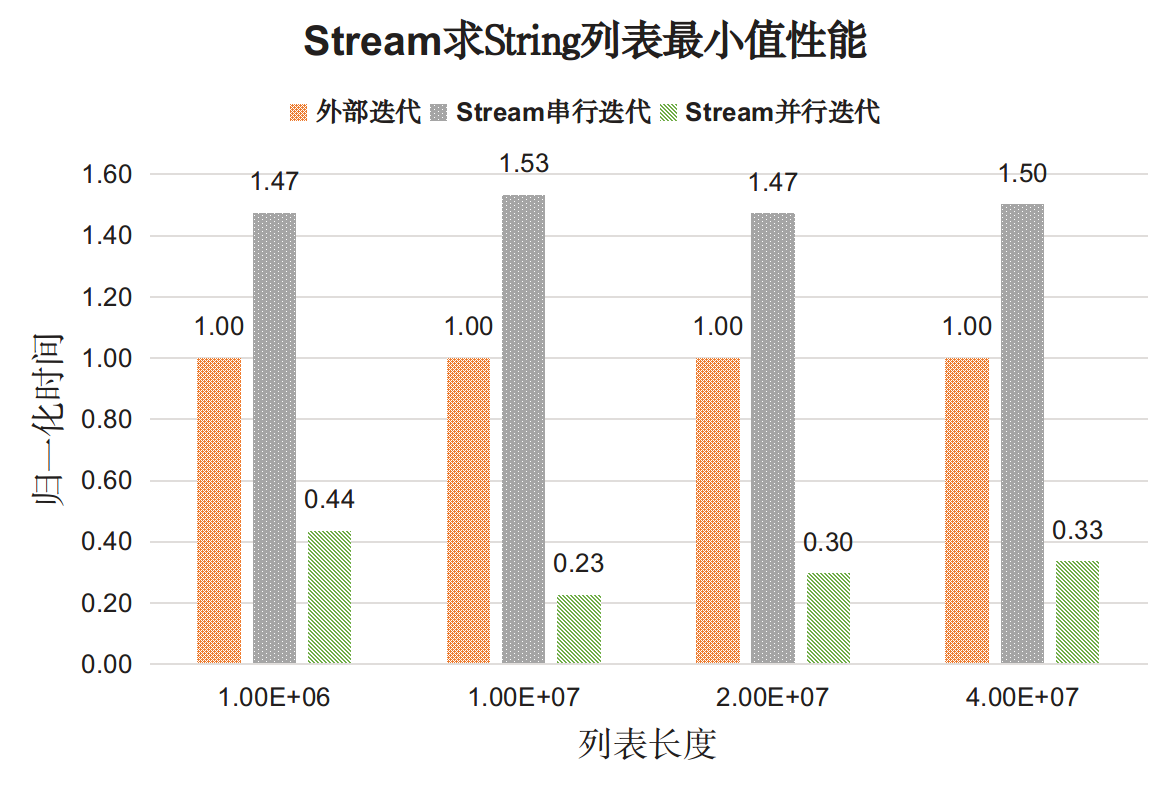
结果分析如下:
- 对于对象类型Stream串行迭代的性能开销仍然高于外部迭代开销(1.5倍),但差距没有基本类型那么大。
- Stream并行迭代的性能比串行迭代和外部迭代都好。
再来单独考察Stream并行迭代效果:
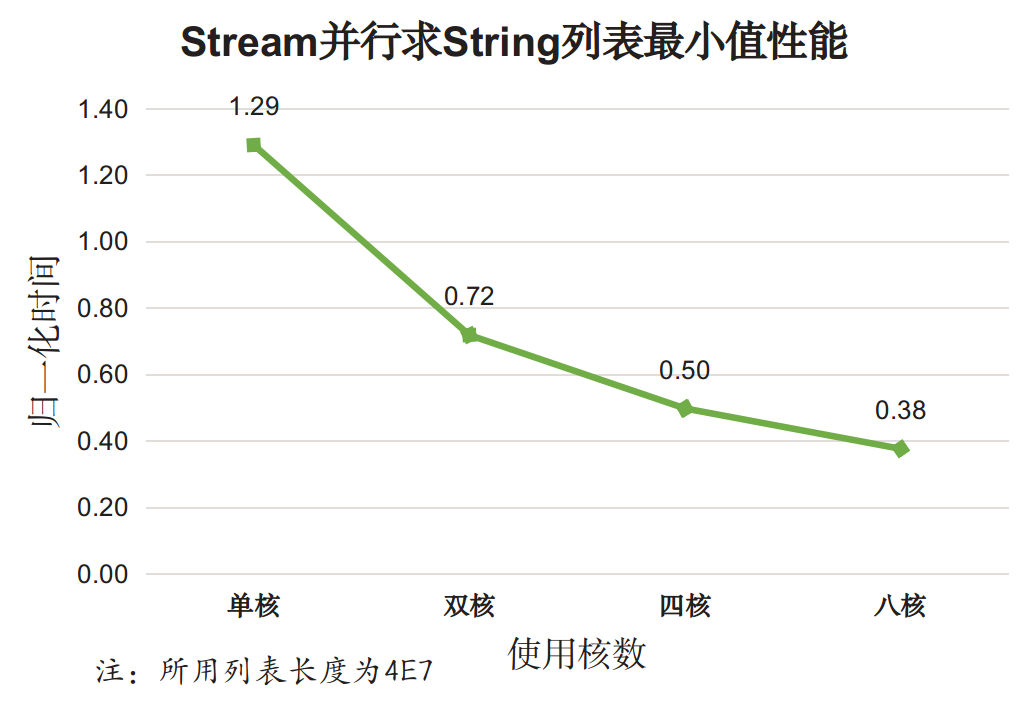
分析,对于对象类型:
- 使用Stream并行API在单核情况下性能比for循环外部迭代差;
- 随着使用核数的增加,Stream并行效果逐渐变好,多核带来的效果明显。
以上两个测试说明,对于对象类型的简单迭代,Stream串行迭代性能更差,但多核情况下Stream迭代时性能较好。
实验三 复杂对象归约
从实验一、二的结果来看,Stream串行执行的效果都比外部迭代差(很多),是不是说明Stream真的不行了?先别下结论,我们再来考察一下更复杂的操作。
测试内容:给定订单列表,统计每个用户的总交易额。对比使用外部迭代手动实现和Stream API之间的性能。
我们将订单简化为<userName, price, timeStamp>构成的元组,并用Order对象来表示。
测试程序代码:
/**
* java -server -Xms10G -Xmx10G -XX:+PrintGCDetails
* -XX:+UseConcMarkSweepGC -XX:CompileThreshold=1000 lee/ReductionTest
* taskset -c 0-[0,1,3,7] java ...
* @author CarpenterLee
*/
public class ReductionTest {
public static void main(String[] args) {
new ReductionTest().doTest();
}
public void doTest(){
warmUp();
int[] lengths = {
10000,
100000,
1000000,
10000000,
20000000,
40000000
};
for(int length : lengths){
System.out.println(String.format("---orders length: %d---", length));
List<Order> orders = Order.genOrders(length);
int times = 4;
Map<String, Double> map1 = null;
Map<String, Double> map2 = null;
Map<String, Double> map3 = null;
long startTime;
startTime = System.nanoTime();
for(int i=0; i<times; i++){
map1 = sumOrderForLoop(orders);
}
TimeUtil.outTimeUs(startTime, "sumOrderForLoop time:", times);
startTime = System.nanoTime();
for(int i=0; i<times; i++){
map2 = sumOrderStream(orders);
}
TimeUtil.outTimeUs(startTime, "sumOrderStream time:", times);
startTime = System.nanoTime();
for(int i=0; i<times; i++){
map3 = sumOrderParallelStream(orders);
}
TimeUtil.outTimeUs(startTime, "sumOrderParallelStream time:", times);
System.out.println("users=" + map3.size());
}
}
private void warmUp(){
List<Order> orders = Order.genOrders(10);
for(int i=0; i<20000; i++){
sumOrderForLoop(orders);
sumOrderStream(orders);
sumOrderParallelStream(orders);
}
}
private Map<String, Double> sumOrderForLoop(List<Order> orders){
Map<String, Double> map = new HashMap<>();
for(Order od : orders){
String userName = od.getUserName();
Double v;
if((v=map.get(userName)) != null){
map.put(userName, v+od.getPrice());
}else{
map.put(userName, od.getPrice());
}
}
return map;
}
private Map<String, Double> sumOrderStream(List<Order> orders){
return orders.stream().collect(
Collectors.groupingBy(Order::getUserName,
Collectors.summingDouble(Order::getPrice)));
}
private Map<String, Double> sumOrderParallelStream(List<Order> orders){
return orders.parallelStream().collect(
Collectors.groupingBy(Order::getUserName,
Collectors.summingDouble(Order::getPrice)));
}
}
class Order{
private String userName;
private double price;
private long timestamp;
public Order(String userName, double price, long timestamp) {
this.userName = userName;
this.price = price;
this.timestamp = timestamp;
}
public String getUserName() {
return userName;
}
public double getPrice() {
return price;
}
public long getTimestamp() {
return timestamp;
}
public static List<Order> genOrders(int listLength){
ArrayList<Order> list = new ArrayList<>(listLength);
Random rand = new Random();
int users = listLength/200;// 200 orders per user
users = users==0 ? listLength : users;
ArrayList<String> userNames = new ArrayList<>(users);
for(int i=0; i<users; i++){
userNames.add(UUID.randomUUID().toString());
}
for(int i=0; i<listLength; i++){
double price = rand.nextInt(1000);
String userName = userNames.get(rand.nextInt(users));
list.add(new Order(userName, price, System.nanoTime()));
}
return list;
}
@Override
public String toString(){
return userName + "::" + price;
}
}
测试结果如下图:
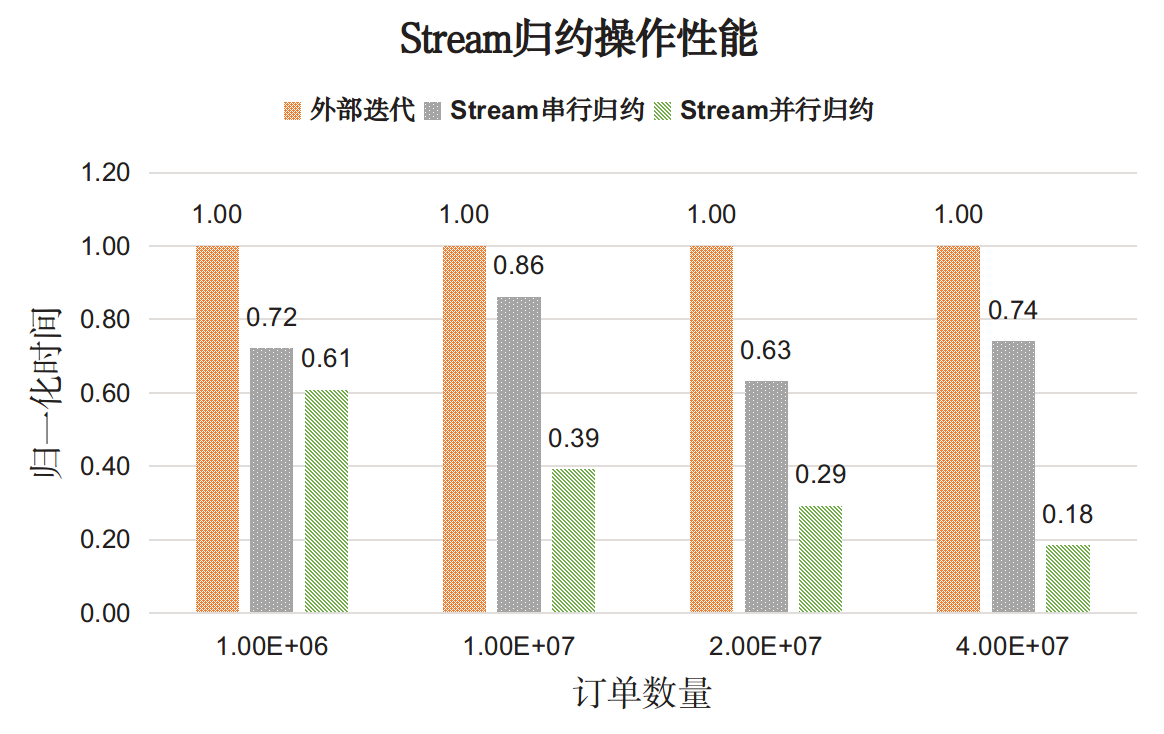
分析,对于复杂的归约操作:
- Stream API的性能普遍好于外部手动迭代,并行Stream效果更佳;
再来考察并行度对并行效果的影响,测试结果如下:
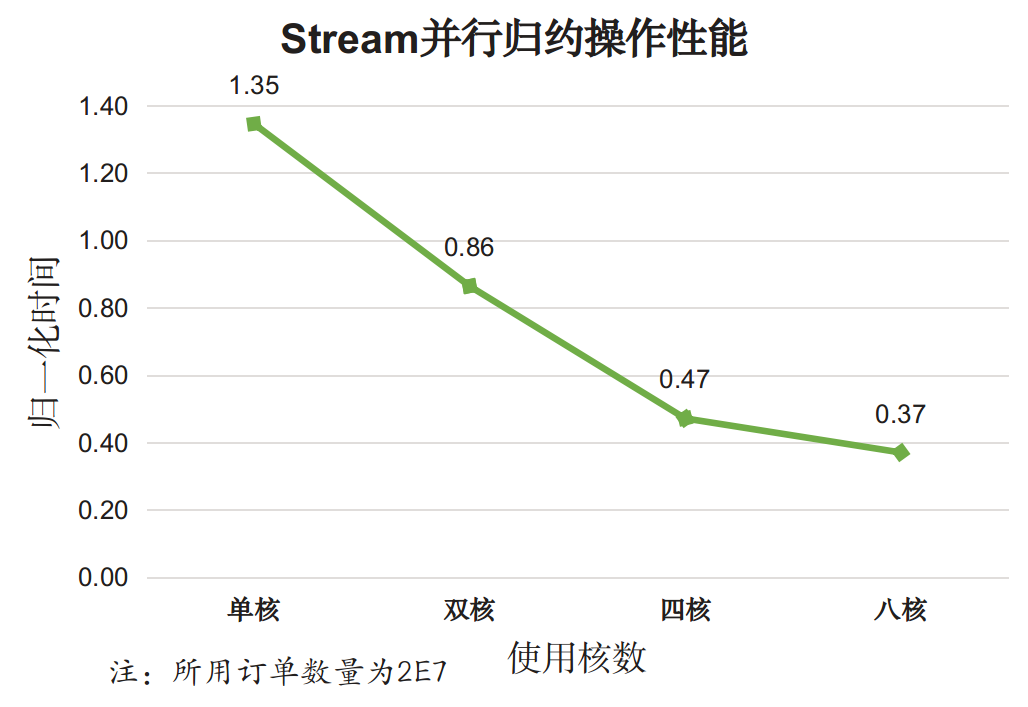
分析,对于复杂的归约操作:
- 使用Stream并行归约在单核情况下性能比串行归约以及手动归约都要差,简单说就是最差的;
- 随着使用核数的增加,Stream并行效果逐渐变好,多核带来的效果明显。
以上两个实验说明,对于复杂的归约操作,Stream串行归约效果好于手动归约,在多核情况下,并行归约效果更佳。我们有理由相信,对于其他复杂的操作,Stream API也能表现出相似的性能表现。
结论
上述三个实验的结果可以总结如下:
- 对于简单操作,比如最简单的遍历,Stream串行API性能明显差于显示迭代,但并行的Stream API能够发挥多核特性。
- 对于复杂操作,Stream串行API性能可以和手动实现的效果匹敌,在并行执行时Stream API效果远超手动实现。
所以,如果出于性能考虑,1. 对于简单操作推荐使用外部迭代手动实现,2. 对于复杂操作,推荐使用Stream API, 3. 在多核情况下,推荐使用并行Stream API来发挥多核优势,4.单核情况下不建议使用并行Stream API。
如果出于代码简洁性考虑,使用Stream API能够写出更短的代码。即使是从性能方面说,尽可能的使用Stream API也另外一个优势,那就是只要Java Stream类库做了升级优化,代码不用做任何修改就能享受到升级带来的好处。