对于大型的分布式系统来说,热点数据一直都是一个需要重点关注的事情,比如热卖商品热点新闻等就都是属于热点数据的。
通常情况下,这种热点数据都会被放在缓存里面,但是如果突然有大量流量需要访问同一个特定的数据,就会导致流量过于集中,使得很多物理资源无法支撑,如网络带宽、物理存储空间、数据库连接等。
这也是为什么某某明星官宣之后,微博上面就会出现宕机的情况。有时候这种宕机发生后,其他功能都是可以使用的,只是和这个热点有关的内容会无法访问,这其实就和热点数据有关系了。
一般情况下,我们会把热点数据缓存下来,而缓存一般都需要有个固定的key,所以,很多时候我们也称这类问题为热key问题。
如何发现热点数据
一般情况下,我们是可以通过一些手段来识别并发现热key的,主要有以下几种方式:
根据经验,提前预测
这种方法在大多数情况下还是比较奏效的。比较常见的就是电商系统中,会在做秒杀、抢购等业务开始前就能预测出热key。
但是,这种方式的局限性也很大,就是有些热key是完全没办法预测的,比如明星什么时候要官宣这种事情就无法预测。
实时收集
还有一种热点数据的发现机制,那就是实时的做收集,比如在客户端、服务端或者在代理层,都可以对实时数据进行采集,然后进行统计汇总。
达到一定的数量之后,就会被识别为热key
如何解决热key问题
解决热key问题最主要的方式就是加缓存。通过缓存的方式尽量减少系统交互,使得用户请求可以提前返回。
这样即能提升用户体验,也能减少系统压力。
缓存的方式有很多,有些数据可以缓存在客户的客户端浏览器中,有些数据可以缓存在距离用户就近的DNS中,有些数据可以通过Redis等这类缓存框架进行缓存,还有些数据可以通过服务器本地缓存进行。
这种使用多个缓存的情况,就组成了二级缓存、三级缓存等多级缓存了。总之,通过缓存的方式尽量减少用户的的访问链路的长度。
有了缓存之后,还会带来一个问题,那就是热点数据如果都被缓存在同一个缓存服务器上,那么这个服务器也可能被打挂。
所以,很多人在加了缓存之后, 还可能同时部署多个缓存服务器,如Redis同时部署多个服务器集群。并且实时的将热点数据同步分发到多个缓存服务器集群中,一旦有的集群扛不住了,立刻做切换。
单纯的对于Redis热key缓存来说,Redis是有分片机制的,同一个热key可能会都保存在同一个分片中,所以还可以在多个分片中都把热key同步一份,使得查询可以同时从多个分片进行,减少某一个分片的压力。
因为有分片,还有一种情况,就是有可能多个热key都会分到同一个分片中,为了减少这种情况的发生,可以增加更多的分片来分担流量。
京东的热key探测
前面简单介绍了热key的发现与解决,这种问题其实最明显的发生就是在电商系统或者像微博这种社交系统中。
所以很多公司内部也有很多成熟的方案。
今天想介绍一个京东内部的框架——JD-hotkey ,这是京东 APP 后台热数据探测框架。
这个框架在Gitee上面开源了(https://gitee.com/jd-platform-opensource/hotkey ),官方描述是这样的:
对任意突发性的无法预先感知的热点数据,包括并不限于热点数据(如突发大量请求同一个商品)、热用户(如恶意爬虫刷子)、热接口(突发海量请求同一个接口)等,进行毫秒级精准探测到。
然后对这些热数据、热用户等,推送到所有服务端JVM内存中,以大幅减轻对后端数据存储层的冲击,并可以由使用者决定如何分配、使用这些热key(譬如对热商品做本地缓存、对热用户进行拒绝访问、对热接口进行熔断或返回默认值)。
这些热数据在整个服务端集群内保持一致性,并且业务隔离,worker端性能强悍。
JD-hotkey探测框架,历经多次高压压测和2020年京东618大促考验。在上线运行的这段时间内,每天探测的key数量数十亿计,精准捕获了大量爬虫、刷子用户,另准确探测大量热门商品并毫秒级推送到各个服务端内存,大幅降低了热数据对数据层的查询压力,提升了应用性能。
该框架历经多次压测,8核单机worker端每秒可接收处理16万个key探测任务,16核单机至少每秒平稳处理30万以上,实际压测达到37万,CPU平稳支撑,框架无异常。
简单点说,这个框架的主要功能就是热数据探测并推送至集群各个服务器。这个框架主要适用于以下场景:
- mysql 热数据本地缓存
- redis 热数据本地缓存
- 黑名单用户本地缓存
- 爬虫用户限流
- 接口、用户维度限流
- 单机接口、用户维度限流限流
- 集群用户维度限流
- 集群接口维度限流
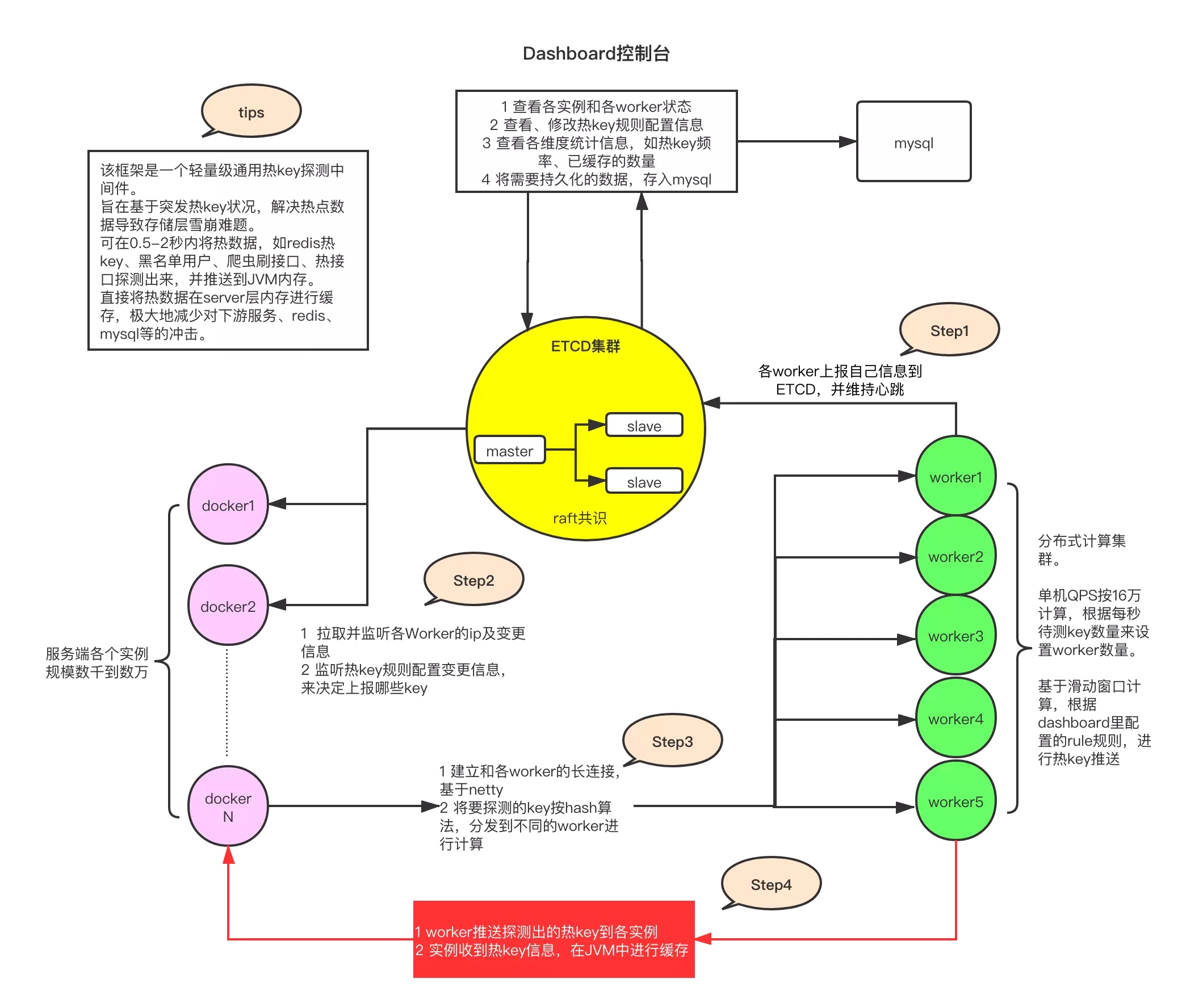
在官方文档中,大概介绍了一下这个框架的工作原理,这个框架主要由四个主要部分,分别是ETCD集群、worker集群、client客户端以及dashboard控制台。
下图介绍了一下各个部分的主要功能及简单原理:

这个框架的使用还是相对简单的,主要分为以下几个步骤:
- 搭建etcd集群
- 启动dashboard可视化界面
- 启动worker集群
- client启动
详情见 https://gitee.com/jd-platform-opensource/hotkey 中的安装教程部分,这里就不详细介绍了。
近日,这个框架在618稳定版0.2版基础上,引入了proto序列化方式,并优化了传输对象。
worker单机性能从618大促稳定版的20万QPS稳定,30万极限,提升至30万稳定,37万极限。且cpu峰值下降了15%。
该中间件目前在京东内部10余个核心部门接入使用,服务于京东App服务端前台、中台,数据中台等多个核心业务线。
最后,目前关于热key的探测方面,京东做的还是不错的,至少他们开源了一个工具出来,给大家多了一个选择。致敬开源,给京东的开源精神点个赞!