之前我们已经详细介绍了关于索引的原理和索引的查询的原则,所谓工欲善其事必先利其器,各位在学习阶段一定要要循序渐进的来学习这块知识,千万不要眼高手低,一定要不急不躁,争取一个萝卜一个坑,学完后能一次性拿下这些知识点,然后再加以运用。
前面的文章我们讨论过,索引的设计要根据 WHERE 条件和 ORDER BY 还有 GROUP BY 后面的字段进行设计,至于原因具体在我前面的文章MySQL索引的原理有详细介绍。这里我们再简单概述下。
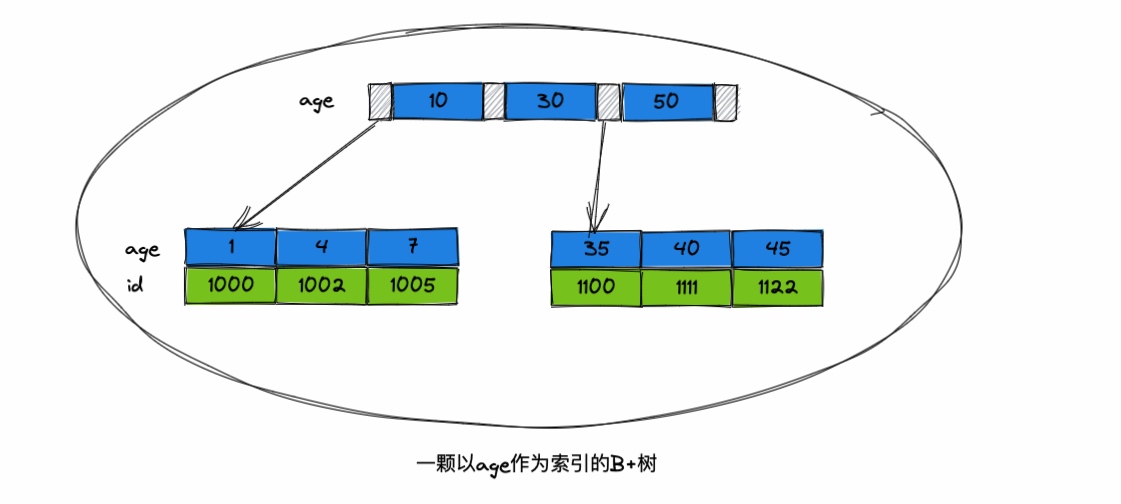
MySQL针对主键索引会维护一个B+树的结构,这个我们称之为聚簇索引,针对非主键(一般都是建立的联合索引)会对索引字段依次排序,然后从第一个字段值开始比较,第一个字段值相同就针对下一个字段值进行比较,依次往后推。
如果联合索引中的字段值都是一样的,那么就根据主键来排序。另外聚簇索引(主键索引)的B+树中保存的是一行记录的所有信息,非聚簇索引(非主键索引)仅仅保存索引字段值和主键字段值。
好了,对于索引原理的回顾我们就介绍到这里,本篇文章,我们继续介绍的是MySQL设置的基本原则,这个也很好理解,就是在设计和建立索引的时候需要遵循哪些原则,按照“标准”去建立索引。今天我们就将关于索引的设计的所有的原则一次性讲清楚。
再多说几句,关于这个知识点,在面试的时候,我经常会问候选人,以此来判断他对索引是不是真的有理解,而不是简单的背八股文!
主键索引
对于主键索引其实是最简单的,但是这里有一些注意的地方还是再啰嗦下。
大家在设计主键的时候一定要是自增的,非常不建议使用UUID作为主键。
为什么?因为UUID是无序的,MySQL在维护聚簇索引的时候都是按照主键的顺序排序的,也就是说每个数据页中的数据一定是按照主键从小到排序的,而且,数据与数据之前是通过单向链表连接的,上一个数据页中的最大的主键的值一定是小于下一个数据页中的最小的主键的值,数据页和数据页之间是通过双向链表来维护的。
我们还是老规矩,画个图帮助大家理解
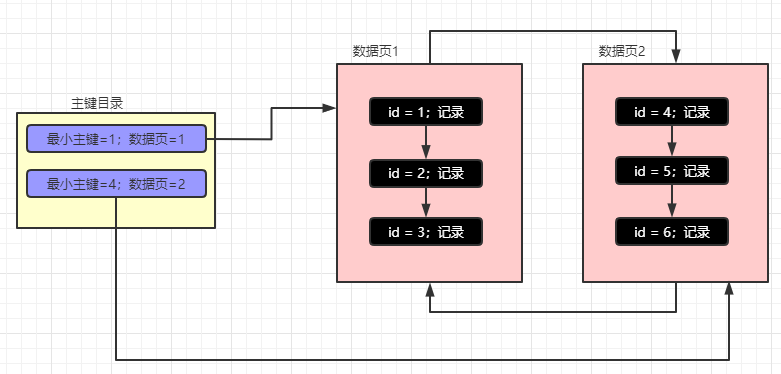
如果主键是自增的,MySQL只需要根据主键目录能很快的定位到新增的记录应该插入到哪里,如果主键不是自增的那么每次都需要从头开始比较,然后找到合适的位置,再将记录插入进去,这样真的严重影响效率,所以主键的设计一定要是自增的。
另外唯一索引和主键索引类似,但是唯一索引不一定是自增的,所以维护唯一索引的成本肯定是大于主键索引的。
但是唯一索引的值是唯一的(唯一索引可以有一个值为 NULL),可以更快的通过索引字段来确定一条记录,但是可能需要进行回表查询(至于什么是回表就不再赘述了,前面文章已经详细的讲解过了)。
为频繁查询的字段建立索引
我们在建立索引的时候,要为那些经常作为查询条件的字段建立索引,这样能够提高整个表的查询速度。
但是查询条件一般不是一个字段,所以一般是建立的联合索引比较多。
另外查询条件中一般会有like这样的模糊查询,如果是模糊查询请最好遵守最左前缀查询原则。
避免为"大字段"建立索引
这个可以换句话说:就是尽量使用数据量小的字段作为索引。
举个例子来说,假设有两个这样的字段,一个是varchar(5),一个是varchar(200),这种情况下优先选择为varchar(5)的字段建立索引,因为MySQL在维护索引的时候是会将字段值一起维护的,那这样必然会导致索引占用更多的空间,另外在排序的时候需要花费更多的时间去对比。
那假如就要为varchar(100)建立索引呢?那就取部分数据,例如 address 类型为varchar(200),在建立索引的时候可以这么写:
CREATE INDEX tbl_address ON dual(address(20));
选择区分度大的列作为索引
这又是什么意思?举个例子相信大家一下子就明白了。
假设现在有一个"性别"字段,里面存放的数据的值要么是男,要么是女,那么这样的字段很不适合作为索引。
这样的字段的值的主要特点就是区分度不够高,而区分度不高的字段不适合做索引,为什么呢?
因为如果值出现的几率几乎相等,那么无论搜索哪个值都可能得到一半的数据。
在这些情况下,还不如不要索引,因为MySQL他还有一个查询优化器,查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。
惯用的百分比界线是"30%"。(匹配的数据量超过一定限制的时候查询器会放弃使用索引(这也是索引失效的场景之一哦)。
这就是原因。所以看到这里相信大家应该知道为什么要尽量避免使用基数小的字段作为索引了吧。其实这里涉及到MySQL的一个专有名词【Cardinality(索引基数)是mysql索引很重要的一个概念】
尽量为ORDER BY 和 GROUP BY 后面的字段建立索引
将 Order By后面的字段建立索引,这样在查询的时候就不需要再去做一次排序了,因为我们都已经知道了建立索引之后在B+树中的记录都是排序好的。
GROUP BY 和 ORDER BY 其实是类似,所以将这两个放在一起说了。
因为在GROUP BY 的时候也要先根据 GROUP BY 后面的字段排序,然后在执行聚合操作。
如果 GROUP BY 后面的字段没有排序,那么这个时候MySQL是需要先进行排序的,这样就会产生临时表,一个排好序的临时表,然后再在临时表中执行聚合操作,这样子当然效率很低了,如果 GROUP BY 后面的字段已经建立了索引,那么MySQL 就不需要再去排序,也就不会产生临时表。
然而比较坑的是,如果 GROUP BY的列和 ORDER BY的列不一样,即使都有索引也会产生临时表,其实对于这些情况我网上搜了下好像还很多,这里我给大家列出来,说实话,这些虽然是标准,但是这个标准好像很难实现,因为实际的场景肯定没这么简单和单纯
1. 如果GROUP BY 的列没有索引,产生临时表.
2. 如果GROUP BY时,SELECT的列不止GROUP BY列一个,并且GROUP BY的列不是主键 ,产生临时表.
3. 如果GROUP BY的列有索引,ORDER BY的列没索引.产生临时表.
4. 如果GROUP BY的列和ORDER BY的列不一样,即使都有索引也会产生临时表.
5. 如果GROUP BY或ORDER BY的列不是来自JOIN语句第一个表.会产生临时表.
6. 如果DISTINCT 和 ORDER BY的列没有索引,产生临时表.
7. GROUP BY 和 ORDER BY 的列一样且是主键,但SELECT 列含有除GROUP BY列之外的列,也会产生临时表
不要在条件中使用函数
如果是已经建立好的索引的字段在使用的时候执行了函数操作,那么这个索引就使用不到了。
这是为什么?
因为MySQL为该索引维护的B+树就是基于该字段原始数据的,如果正在使用过程中加了函数,MySQL就不会认为这个是原来的字段,那肯定不会走索引了。
但是如果有人就犟,那我就要使用到函数怎么办?总不能为了索引而改变业务啊?如果是使用MySQL内部函数导致索引失效的,那么在建立索引的时候可以连着函数一起创建。
这又是什么意思?假设有一个字段叫age,并为其创建了索引,但是使用的时候是这样子的
SELECT * FROM student WHERE round(age) = 2;
这个时候索引是使用不到的,那么如果真的非要让round(age)也走索引,那么你可以这么创建索引
create index stu_age_round on test(round(age));
这个时候在通过上面的方式去查询,索引就是生效的,相信这个大家是能想明白的。
不要建立太多的索引
因为MySQL维护索引是需要空间和耗费性能的,MySQL会为每个索引字段维护一颗B+树。
所以如果索引过多,这无疑是增加了MySQL的负担。
频繁增删改的字段不要建立索引
这个就很好理解了,因为我们前面早就介绍过,字段的变化MySQL是需要重新维护索引的。
假设某个字段频繁修改,那就意味着需要频繁的重建索引,这必然影响MySQL的性能啊。这里不再多说了。
说到这里大部分说的是所以设计的时候需要注意的一些原则,其实真正的原则还是需要根据实际的业务变更的,没有所谓的“公式”,只要适合自己实际的业务场景的设计才是最好的。所以大家也不要过于追求“优化”,因为这样往往会适得其反,毕竟脱离了业务谈技术就是在耍流氓。
好了下面我们再来一起重点看看哪些情况下索引会失效。(PS:本文基本全是理论,我想画图来表达,结果发现根本无法下手希望大家再坚持下,就快完事了。)
索引失效的常见场景
- 使用
OR关键字会导致索引失效,不过如果要想使用OR 又不想让索引失效,那就得需要为or条件中的每个列都建立索引。这很显然是和上面的不要建立太多的索引相违背。 - 联合索引如果不遵循最左前缀原则,那么索引也将失效
- 使用模糊查询的时候以%开头也会导致索引失效(这里就不再重复原因了,因为前面的文章都是说过了,这里就是为了帮助大家再会回忆下)
- 索引列如果使用了隐式转换也会导致索引失效
假设字段 age 类型为 int,那我们一般是这么查询的
SELECT * FROM student WHERE age=15
上面这种情况是能使用到索引的,但是如果你这么写
SELECT * FROM student WHERE age='15'
那这种情况是使用不到索引的,也就是age列情的索引是失效的。
如果字段基数小也可能会导致索引失效,具体在本文的上面部分已经详细解释了,也就是MySQL 查询优化器导致的。
其他的一些原则请大家还是要去看下索引的原理和查询的基本原则,如果没有前面的铺垫,这些看起来似乎有些空洞。所以请大家在索引这一块一定要循序渐进的学习,这一块基本也是我们平时在使用MySQL时候的一些核心知识点了。